Open MARS Dataset
- 摘要
- 引言
- Dataset Curation
- Vehicle Setup
- Data Collection
- Dataset Statistics
- Benchmark Task and Model
- Place Recognition
- Neural Reconstruction
- Experimental Results
- Visual Place Recognition
- Neural Reconstruction
- Opportunities and Challenges
- 结论
摘要
大规模数据集推动了基于人工智能的自动驾驶汽车研究的最新进展。然而,这些数据集通常是从单个车辆一次性通过某个位置收集的,缺乏多智能体交互或同一地点的重复穿越。这些信息可以带来自动驾驶汽车感知、预测和规划能力的变革性增强。为了弥补这一差距,我们与自动驾驶公司May Mobility合作,提出了MARS数据集,该数据集统一了多Agent、多行程和多模式自动驾驶汽车研究的场景。更具体地说,MARS是由在特定地理区域内行驶的自动驾驶汽车车队收集的。每辆车都有自己的路线,不同的车辆可能会出现在附近的位置。每辆车都配备了激光雷达和环绕RGB摄像头。我们在MARS中策划了两个子集:一个子集有助于多辆车同时出现在同一位置的协同驾驶,另一个子集通过多辆车对同一位置进行异步遍历来实现记忆回顾。我们进行了原位识别和神经重建实验。更重要的是,MARS引入了新的研究机遇和挑战,如多遍历3D重建、多智能体感知和无监督对象发现。我们的数据和代码可以在https://ai4ce.github.io/MARS/.
引言
现有的驾驶数据集通常关注地理和交通多样性,而没有考虑两个实际维度:多智能体(协作)和多遍历(回顾)。协作维度强调了位于同一空间区域的多辆汽车之间的协同作用,促进了它们的合作感知、预测和规划。回顾维度使车辆能够通过借鉴以前访问同一地点的视觉记忆来增强对3D场景的理解。采用这些维度可以解决在线感知能力有限和离线重建的稀疏视图等挑战。
然而,现有的数据集通常是由单个车辆在一次穿越特定地理位置时收集的。为了推进自动驾驶汽车的研究,特别是在协作和回顾方面,研究团体需要一个更全面的真实驾驶场景数据集。为了填补这一空白,我们引入了Open MARS数据集,它提供了MultiAgent、multitraveRSal和多模态记录,如图1所示。所有的记录都来自May Mobility1在现实世界中运行的自动驾驶汽车。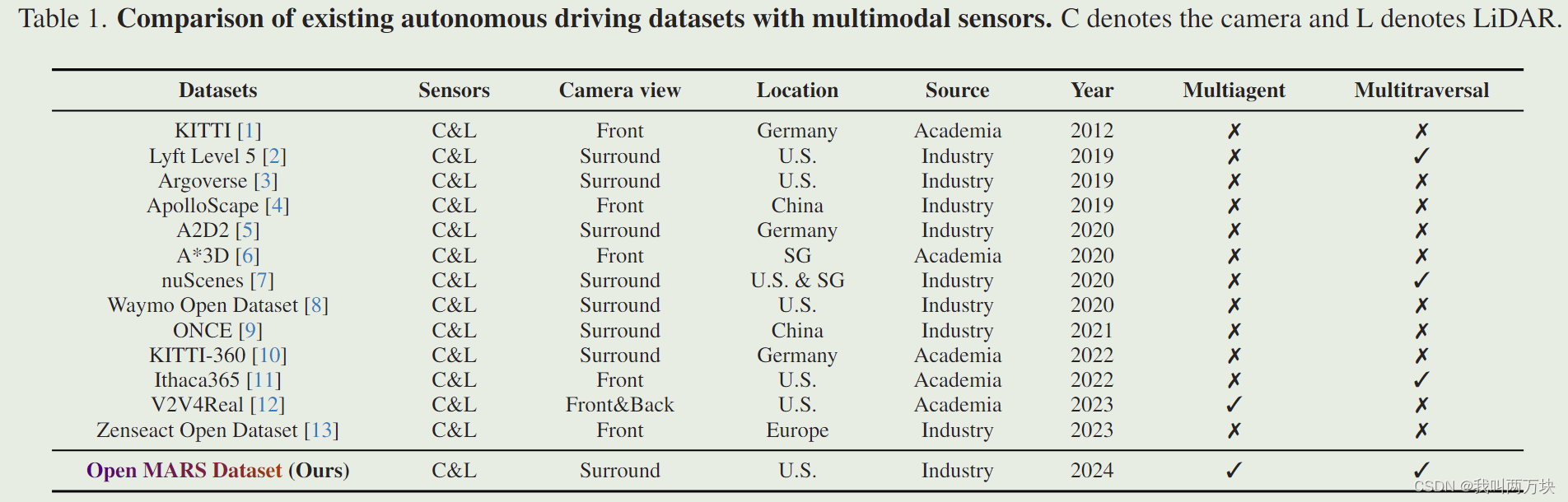
- 多智能体。我们部署了一组自动驾驶汽车来导航指定的地理区域。这些车辆可以同时处于相同的位置,允许通过车辆到车辆的组合进行协作 3D 感知。
- 多遍历。我们在不同的照明、天气和交通状况下捕获同一空间区域内的多次遍历。每个遍历可能遵循一条独特的路线,覆盖不同的行驶方向或车道,从而产生多个轨迹,为3D场景提供不同的视觉观察。
- 多模态。我们为自动驾驶汽车配备了 RGB 相机和 LiDAR,两者都具有完整的 360 度视野。这种全面的传感器套件可以实现多模态和全景场景理解。
我们对位置识别和神经重建进行了定量和定性实验。更重要的是,MARS 为视觉和机器人社区引入了新的研究挑战和机遇,包括但不限于多智能体协作感知和学习、重复遍历下的无监督感知、持续学习、神经重建和具有多个代理或多个遍历的新颖视图合成。
Visual place recognition.在计算机视觉和机器人领域,视觉位置识别(VPR)非常重要,它可以根据视觉输入识别特定的位置[34]。具体来说,VPR系统的功能是将给定的查询数据(通常是图像)与现有的参考数据库进行比较,并检索与查询最相似的实例。该功能对于在gps不可靠的环境中操作的基于视觉的机器人至关重要。VPR技术一般分为两类:传统方法和基于学习的方法。
- 传统方法利用手工制作的特征[35,36]来生成全局描述符[37]。然而,在实际应用中,外观变化和视点有限会降低VPR的性能。
- 为了解决外观变化的挑战,基于学习的方法利用深度特征表示[38-40]
除了基于图像的VPR之外,还提出了基于视频的VPR方法[41-43],以获得更好的鲁棒性,减轻视频片段的有限视点。此外,CoVPR[44]为VPR引入了协作表示学习,弥合了多智能体协作和位置识别之间的差距,并通过利用合作者的信息解决了有限的观点。除了2D图像输入,PointNetVLAD[45]探索了基于点云的VPR,为位置识别提供了独特的视角。在本文中,我们评估了单智能体VPR和协作VPR。
NeRF for autonomous driving. 无界驾驶场景中的神经辐射场(Neural radiance fields, NeRF)[46]最近受到了很多关注,因为它不仅促进了高保真神经模拟器的开发[16],而且还实现了环境的高分辨率神经重建[47]。关于新视图合成(NVS),研究人员已经解决了一些挑战,如使用局部块的可扩展神经表示[48,49],使用组合字段的动态城市场景解析[50,51],以及使用对象感知字段的全景场景理解[52,53]。在神经重建方面,研究人员已经实现了基于LiDAR点云和图像输入的较好的表面重建[54,55]。同时,在不依赖激光雷达的多视点隐式表面重建方面也做了一些努力[47]。现有基于NeRF的方法受到有限的视觉观察的限制,通常依赖于沿着狭窄轨迹收集的稀疏相机视图。利用额外的摄像机视角(无论是来自多个代理还是重复遍历)来丰富视觉输入并增强NVS或重建性能,这方面存在着巨大的未开发潜力。
Dataset Curation
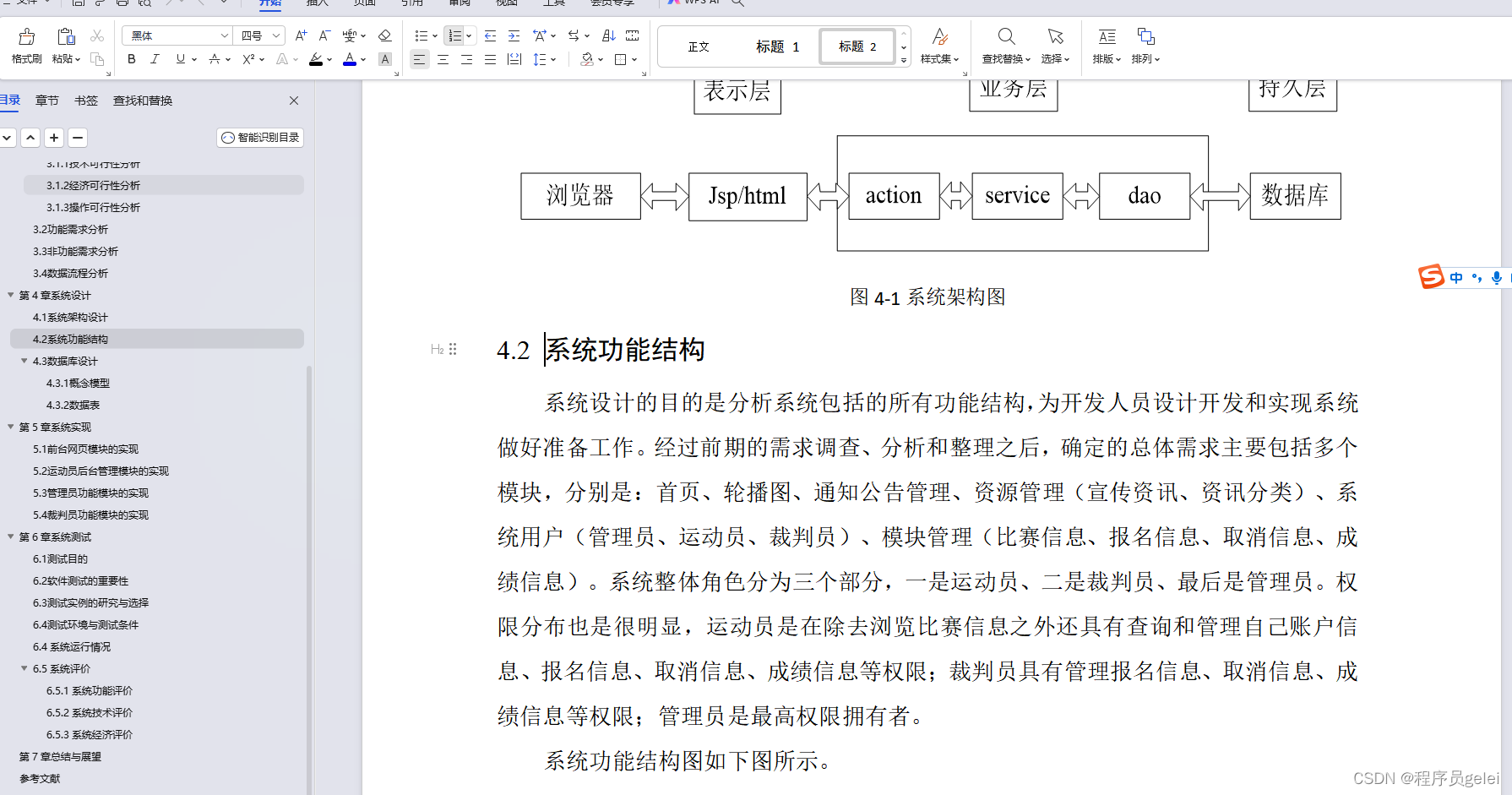
Vehicle Setup
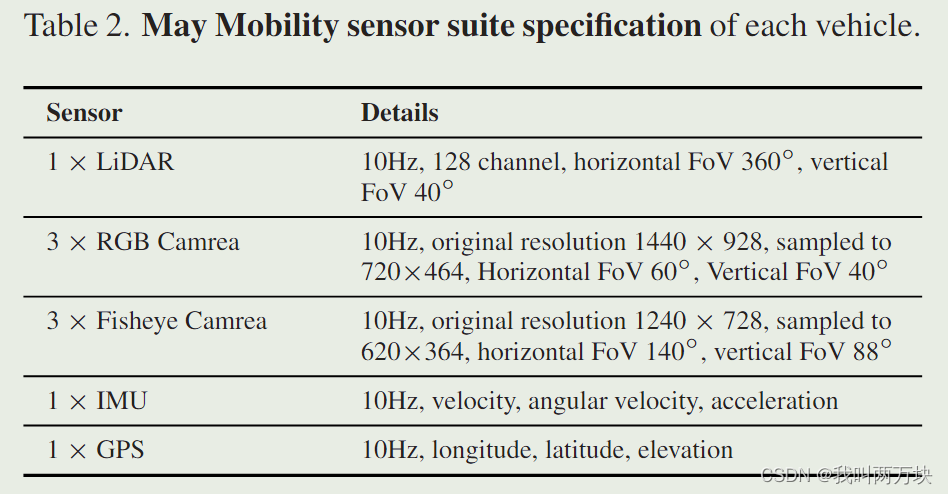
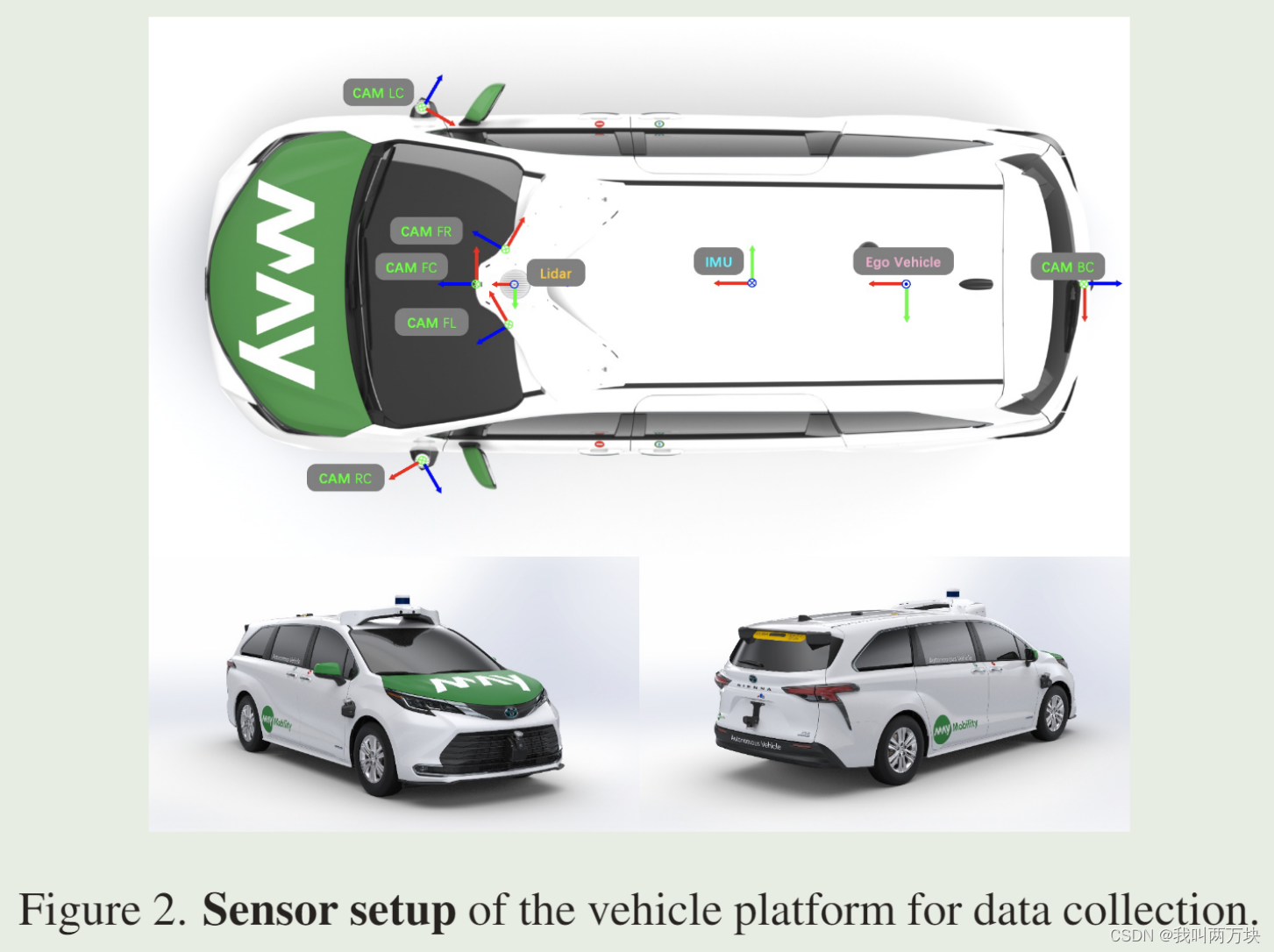
传感器设置。 May Mobility的车队包括四辆丰田Sienna,每辆都安装了一个激光雷达、三个窄角RGB摄像头、三个广角RGB鱼眼摄像头、一个IMU和一个GPS。传感器具有各种原始输出频率,但所有传感器数据最终被采样到10Hz以进行同步。相机图像被下采样以节省存储空间。这些传感器的详细规格如表2所示。一般来说,激光雷达位于车辆的前顶部。三个窄角摄像头分别位于车辆的前部、前部左侧和前部右侧。三个鱼眼摄像头分别位于车辆的后部中心、左侧和右侧;见图2。IMU和GPS位于车辆的中央顶部。这些传感器的显性外在表现为旋转和平移,将传感器数据从其自身的传感器框架转换为车辆的自我框架。对于每辆车上的每个摄像头,我们提供了摄像头的固有参数和畸变系数。畸变参数通过AprilCal校准方法推断[56]。
坐标系统。 有四种坐标系:传感器框架、自我框架、局部框架和全局框架。传感器框架表示原点定义在单个传感器中心的坐标系。自我框架代表坐标系统,其原点定义在自我车辆后轴的中心。本地框架表示坐标系统,其原点定义为自我车辆当天轨迹的起点。全局坐标系是世界坐标系。
Data Collection
May Mobility目前专注于微服务交通,在固定路线上运行各种订单和方向的穿梭车。整个路线长达20多公里,包括住宅、商业和大学校园,在交通、植被、建筑和道路标志方面有着不同的环境。船队的运作时间为每日下午二时至八时,因此可应付各种光照及天气情况。总的来说,May Mobility独特的操作模式使我们能够收集多遍历和多智能体的自动驾驶数据。
多遍历数据收集。 我们在驾驶路线上总共定义了67个地点,每个地点都横跨半径50米的圆形区域。这些地点涵盖了不同的驾驶场景,如十字路口,狭窄的街道,以及各种交通状况的长直道路。每个地点的穿越在每天的不同时间从不同的方向进行,保证了对该地区的物理和时间的全面感知。我们通过车辆的GPS定位来确定它是否正在经过目标位置,并收集车辆在50米半径范围内存在的整个时间内的数据。对遍历进行过滤,使每次遍历的时间在5秒到100秒之间。
多代理数据收集。 我们数据集的一个亮点是,我们提供了真实世界的同步多智能体协作感知数据,提供了极其详细的空间覆盖。从车辆的GPS坐标确定,我们提取30秒长的场景,其中两辆或更多的自我车辆彼此距离小于50米超过9秒,共同提供同一时间从不同角度对同一区域的重叠感知。持续不到整整30秒,相遇片段被放置在30秒持续时间的中心,在它之前和之后填充等量的非相遇时间(例如,20秒的相遇通过增加之前的5秒和之后的5秒而扩展到30秒的场景)。这种遭遇可以发生在地图周围的任何地方,构成了沿着笔直道路尾随和在十字路口相遇的场景,如图7所示。我们的方法还确保场景中至少有一辆车在30秒内行驶超过10米。
Dataset Statistics
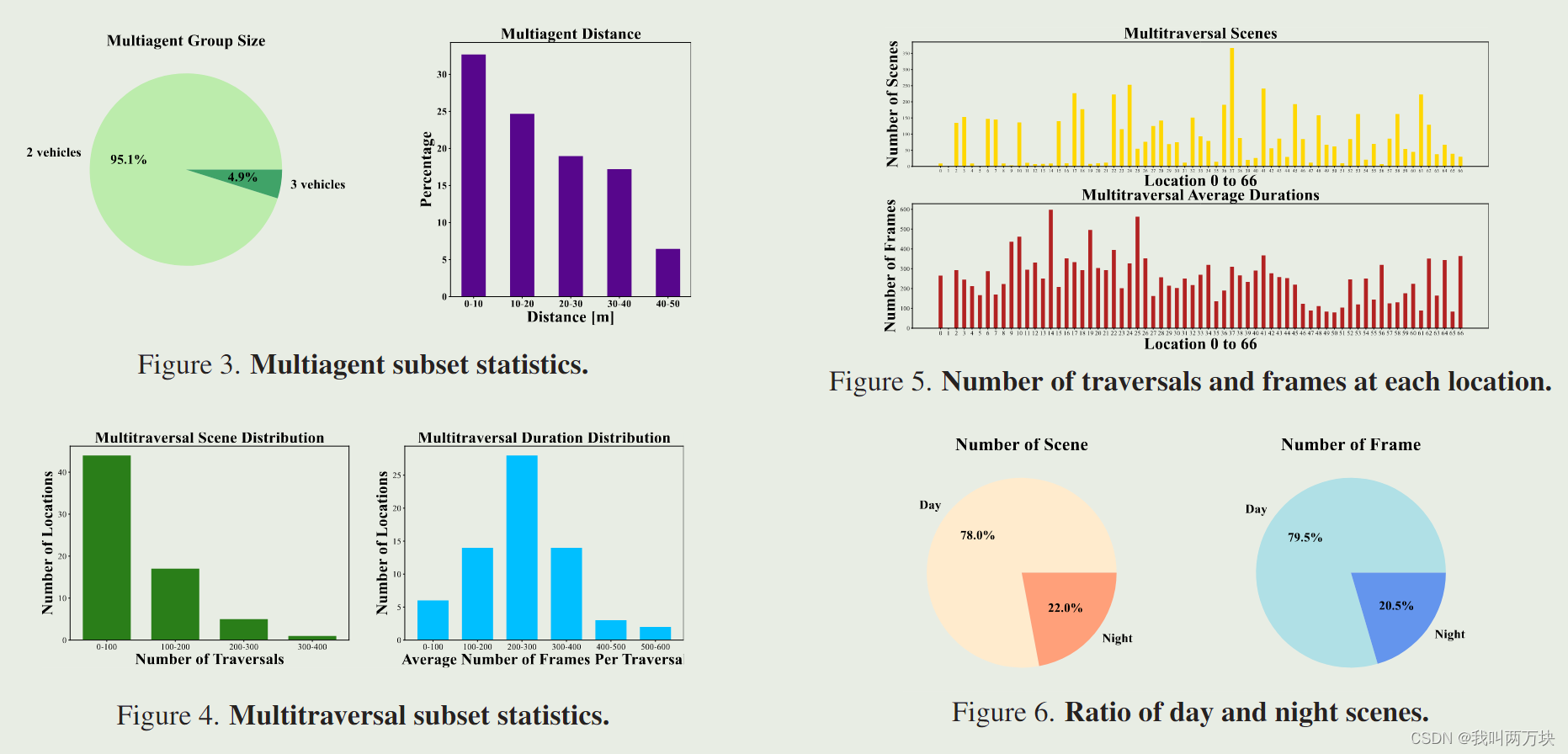
多观测子集涵盖了2023年10月4日至2024年3月8日期间26个不同日子的数据,其中4个是雨天。我们总共收集了5757次遍历,每个相机和360度激光雷达点云包含超过140万帧的图像。在67个地点中,48个地点有超过20条路线,23个地点有100条路线,6个地点有200条路线。每次遍历平均有250帧(25秒),大多数遍历包含100到400帧(10到40秒)。所有位置的横向和框架的具体分布如图4和图5所示。muitlagent子集涵盖了2023年10月23日至2024年3月8日期间20个不同日期的数据。我们收集了53个持续时间为30秒的场景,每个场景稳定地涉及297到300帧,总共超过15000帧的图像和激光雷达点云。在53个场景中,52个场景涉及两辆车,1个场景涉及三辆车。对于每一帧,分析每对自我车辆之间的距离。分布表明,相遇大多发生在两辆车相距不到50米的情况下,如图3所示。
Benchmark Task and Model
Place Recognition
问题定义。 我们考虑具有M个图像的一组查询Q和具有N个图像的参考数据库D。在这个任务中,目标是在给定Iq∈Q的情况下找到Ir∈D,使得Iq和Ir在同一位置被捕获。
评估指标。我们采用K的召回率作为VPR的评估指标。对于查询图像Iq,我们选择具有Xqand{Xr}Nr=1之间的Top-K余弦相似性的K个参考图像。如果至少有一个选定的图像是在Iq的S米范围内拍摄的(本文中S=20),则我们将其视为正确的。K处的召回率计算为正确计数总数与M之间的比率。
基准模型。 我们采用NetVLAD[38]、PointNetVLAD[45]、MixVPR[39]、GeM[57]、Plain ViT[58]和CoVPR[44]作为基准模型。
- NetVLAD由基于CNN的主干网和NetVLAD池化层组成。NetVLAD用可学习的软分配取代了VLAD[37]中的硬分配,将骨干提取的特征作为输入,并生成全局描述符。
- MixVPR由一个基于CNN的主干网和一个功能混合器组成。主干的输出被平坦化为C×H′W′,用行和列MLP馈送到特征混合器,平坦化为单个矢量,并进行L2归一化。
- PointNetVLAD由主干网、NetVLAD池和MLP组成。我们将主干的输出维度从1024减少到256,并省略了最后一个MLP层,以实现高效计算
- GeM由一个基于CNN的主干网和一个GeM池组成。GeM池被定义为1N(PN i=1 Xp i)1p,其中Xi是补丁功能,我们在这里选择p=3。
- Plain ViT[58]由标准变换器编码器层和cls-toekn上的L2归一化组成。
- CoVPR[44]由VPR模型和相似规则融合组成。VPR模型为自我代理和合作者生成描述符,融合模块将它们融合为一个描述符。
Neural Reconstruction
问题定义。 根据可用遍历的数量,我们将重建任务分为两个场景。第一种是单遍历(动态场景重构指令),其中输入是作为一个遍历视频捕获的图像序列I={I1,I2,···Ik}。目标是重建照片级真实感场景视图,包括移动对象。第二种是多重遍历(环境重建),其中输入是同一场景的图像序列{I1,I2,···,In:Im={Im,1,··,Im,km}}的集合。此任务的目标是重建环境并移除动态对象。
评估指标。基于早期工作中使用的方法[59]。我们使用PSNR、SSIM和LPIPS度量进行动态重建实验。PSNR,定义为P SN R=10·log10 M AX2IM SE,通过比较最大像素值M AXI和均方误差M SE来评估图像质量。SSIM,通过SSIM(x,y)=(2μxμy+c1)(2σxy+c2)(μ2x+μ2y+c1。与之前的两种度量不同,LPIPS使用预训练的神经网络模型来评估两幅图像之间的感知相似性。
基准模型。 对于单个遍历任务,我们采用EmerNeRF[60]和PVG[59]作为基准模型。此外,为了进行比较,我们使用iNGP[61]和3DGS[62]进行了实验,它们并没有直接针对这个问题。关于多遍历重建,没有专门为此任务设计的算法。因此,我们采用iNGP作为基本模型。此外,为了增强模型去除动态对象的能力,我们还用Segformer[64]测试了RobustNeRF[63]和iNGP。
单次遍历:动态场景重建。
- EmerNeRF。EmerNeRF是一种基于神经场的自监督方法,用于有效地学习动态驾驶场景的时空表示。EmerNeRF通过将场景分解为静态和动态场来构建混合世界表示。通过利用突发流场,可以进一步聚合时间信息,提高动态组件的渲染精度。2D视觉基础模型特征被提升到4D时空中,以增强EmerNeRF的语义场景理解PVG。
- 在3DGS的基础上,PVG将周期性振动引入每个高斯点,以对这些点的动态运动进行建模。为了处理对象的出现和消失,它还为每个点设置了时间峰值和寿命。通过学习所有这些参数,以及高斯的平均值、协方差和球面谐波,PVG能够以高效记忆的方式重建动态场景。
多重遍历:
- 环境重建RobustNeRF RobustNeRF取代了原始NeRF的损失函数来忽略干扰物,在我们的情况下,我们将动态对象视为干扰物。
- 此外,RobustNeRF在其损失估计器中应用了一个盒核,以防止高频细节被识别为异常值SegNeRF。SegNeRF利用预训练的语义模型SegFormer[64]来去除可移动对象。
Experimental Results
Visual Place Recognition
数据集的详细信息。 我们用多遍历和多智能体数据对VPR任务进行了实验。在多次遍历的情况下,编号大于或等于52的十字路口用于测试。在多智能体设置中,使用大于或等于50的场景进行测试。输入图像大小调整为400 × 224,输入点云降采样到1024点。
实现细节。我们在第4节中提到的模型上评估我们的数据集,其中CoVPR[44]是用多智能体数据评估的,所有其他数据都是用多遍历数据评估的。在ImageNet1K上对主干进行预训练[65]。我们使用ResNet18[66]作为NetVLAD和CoVPR的主干,使用ResNet50[66]作为MixVPR和GeM的主干,使用PointNet[67]作为PointNetVLAD的主干。基于netvlad的方法中集群数量为32个。使用Adam[68]优化器训练模型,PointNetVLAD使用1e- 3lr,其他使用1e- 4lr,衰减率为1e-4,直到收敛。基于netvlad的方法的批大小为20,其他方法的批大小为10。
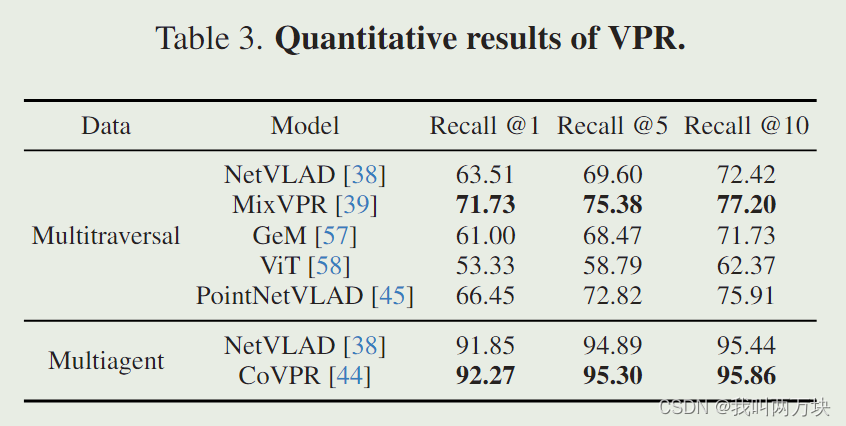
结果讨论。定量结果见表3。虽然GeM在其池化方法中实现了轻量级特性,但与骨干较小的NetVLAD相比,它的性能较差。尽管ViT是比ResNet更强大的骨干网络,但在没有特定于任务的池化方法的情况下,ViT在VPR中的性能较弱。MixVPR实现了最好的性能,因为它的特性混合机制提供了更丰富的特性。PointNetVLAD利用点云,在比NetVLAD更小的输入尺寸下获得更好的性能。在多代理数据的上下文中,CoVPR始终优于其单代理对应物。定性结果如图8所示。我们的数据集包括白天和夜间的场景,在各种天气条件下,如晴天、多云和雨天。难以置信的例子来自夜间场景和受雨或背光影响的相机。

Neural Reconstruction
数据集的详细信息。在我们的单遍历动态场景重建实验中,我们选择了10个不同的位置,每个位置都有一次遍历,旨在捕捉和表示复杂的城市环境。对于我们的多遍历环境重建实验,我们总共选择了50遍历。这包括10个独特的位置,每个位置有5个遍历,使我们能够捕捉光照条件和天气的变化。
实现细节。在所有重建实验中,我们利用来自三个前置摄像头的100张图像以及激光雷达数据作为每次遍历的输入。单遍历实验:iNGP和EmerNeRF模型都使用Adam[68]优化器进行10,000次迭代训练,学习率为0.01,权重衰减率为0.00001。对于EmerNeRF,我们利用DINOv2 viti - b /14[69]基础模型中的恐龙特征。该模型采用了线性视差和均匀采样相结合的PropNet估计器。对于3DGS和PVG,我们设置训练迭代次数为20000次,学习率与原文相同[59]。我们将3DGS视为PVG方法的特例,其周期运动幅度为0,寿命无限,我们在实验中将其设置为106。多遍历实验:本实验中我们的NeRF模型是iNGP[61],具有图像嵌入和DINO特征。对于RobustNeRF,我们实现了原论文[63]中描述的鲁棒损失和补丁样本。在segerf中,我们应用了在cityscape[70]数据集上训练的SegFormer-B5[64]模型。在SegFormer模型中的19个类别中,我们将“人”、“骑手”、“汽车”、“卡车”、“公共汽车”、“火车”、“摩托车”和“自行车”识别为动态类,并为它们生成掩码。
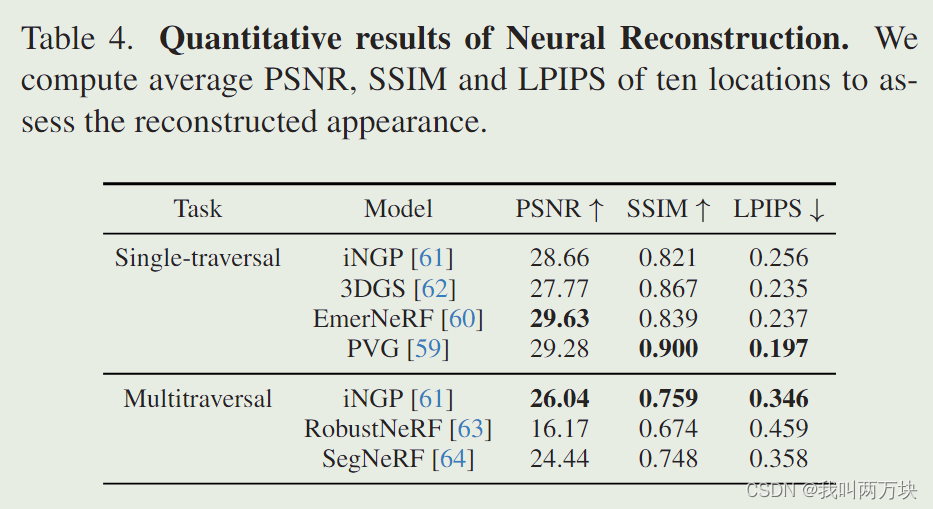
结果讨论。Single-traversal实验:在表4的结果中,PVG的SSIM得分较高,LPIPS得分较好,说明结构细节得到了增强。PVG的优异性能可能归功于其灵活的高斯点设置,它熟练地捕捉线性运动,以及物体的出现和消失。另一方面,EmerNeRF在PSNR方面表现出色。这可能是由于它的动态-静态分解的新方法。如图9所示,EmerNeRF和PVG都展示了完美渲染动态物体(如移动的汽车)的能力,而iNGP和3DGS在这方面表现相对较差。多遍历实验:由于图像嵌入,iNGP可以渲染不同的照明场景。然而,它很难准确地呈现动态对象或删除它们。如表4所示,iNGP实现了最好的相似性度量,因为它保留了关于动态对象的最多信息。RobustNeRF在消除动态对象方面表现最好,尽管以渲染较少细节的静态对象为代价。与其他两种方法相比,利用语义信息的SegFormer获得了更好的视觉效果。然而,汽车的阴影并没有被完全去除,这可能是由于语义分割模型对阴影的识别不足。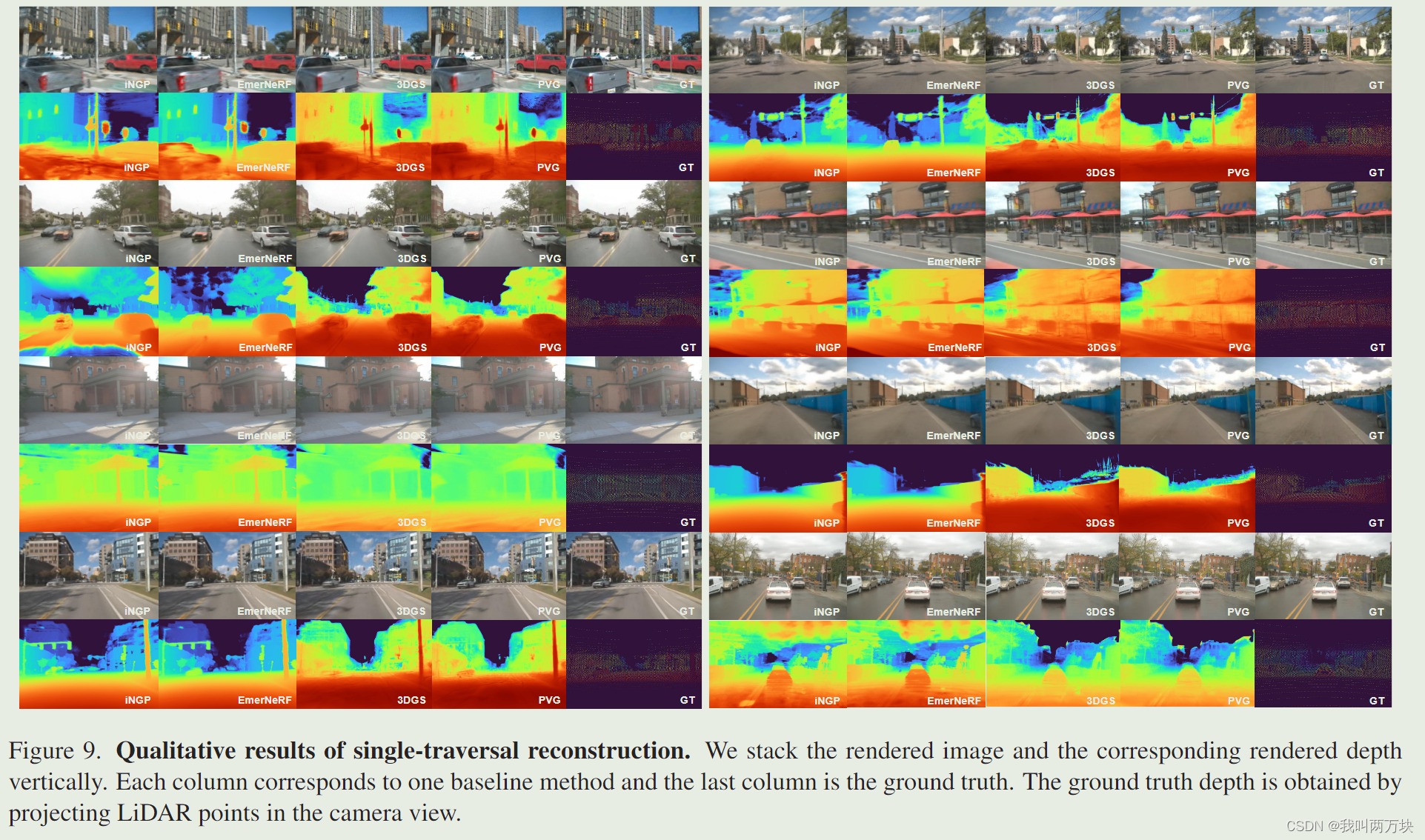
Opportunities and Challenges
我们的MARS数据集引入了新的研究机会,包括多智能体驾驶记录,以及对同一位置的大量重复遍历。我们概述了几个有前景的研究方向及其相关挑战,为未来的研究开辟了新的途径。
3d重建。重复遍历可以为3D场景产生大量的相机观察,促进多视图重建中的对应搜索和束调整。我们的数据集可以用于研究仅相机的多遍历三维重建,这对于自主映射和定位至关重要。主要的挑战是处理随时间重复遍历的外观变化和动态对象。
神经模拟。多代理和多遍历记录对于制作可以重建和模拟场景和传感器数据的神经模拟器非常有价值。高保真仿真对于开发感知和规划算法至关重要。主要的挑战在于复制真实世界的动态和可变性,例如对动态对象的行为、环境条件和传感器异常进行建模,确保模拟数据提供全面和真实的测试平台。
无监督。利用场景先验在无监督3D感知中具有重要的价值,特别是在多遍历驾驶场景中,来自先验访问的丰富数据可以增强在线感知。随着时间的推移,这种方法不仅可以通过知识的积累来更深入地理解环境,而且还可以实现无监督的感知,而无需使用手动注释进行训练。
结论
我们的MARS数据集代表了自动驾驶汽车研究的显著进步,通过集成多智能体、多遍历和多模态维度,超越了传统的数据收集方法。MARS为探索3D重建和神经模拟、协同感知和学习、具有场景先验的无监督感知等开辟了新的途径。未来的工作包括为在线感知任务提供注释,如多智能体和多遍历场景下的语义占用预测。我们坚信,MARS将在人工智能驱动的自动驾驶汽车研究领域树立新的标杆。